
By Brian French
Why NVIDIA’s Blackwell and Vera Rubin GPUs Are Worth Every Penny
Einstein vs. the Substitute Teacher: Why NVIDIA’s Blackwell and Vera Rubin GPUs Are Worth Every Penny
The price tag on NVIDIA’s latest chips looks shocking — until you understand what you’re actually buying.
The Intelligence Gap Nobody Talks About
Imagine you need to solve the most complex problem your business has ever faced — pricing a new product line across 40 markets, optimizing a supply chain with 10,000 variables, or drafting a legal strategy that anticipates six counterarguments. You have two options for who you bring into the room.
Option one: a substitute teacher. Smart enough, certainly. Willing to help. But when the problem exceeds their ceiling, they slow down, simplify, hedge, and eventually shrug.
Option two: Albert Einstein.
That is not a metaphor. That is, functionally, the choice NVIDIA has placed in front of every organization building AI infrastructure today. Competing chips give you the substitute teacher. Older GPU generations give you a decent college professor. NVIDIA’s Blackwell platform gives you a tenured physicist at a world-class research university. And Vera Rubin — arriving in the second half of 2026 — gives you Einstein running at a thousand times the speed of a human mind, at one-tenth the cost per thought it takes to rent one.
When you frame it that way, the price of NVIDIA’s chips stops looking like a premium. It starts looking like the only rational choice.
The Only Number That Matters: Cost Per Token
In AI infrastructure, the unit of output is the token — a word in a response, a reasoning step in an agentic workflow, a decision made by an automated system. Everything in an AI data center exists to produce tokens as cheaply and as quickly as possible. The building, the power lines, the cooling systems, the fiber cables — all of it is overhead. The GPU is the only component that actually generates the output.
So when evaluating any GPU, one number cuts through all the noise: cost per million tokens generated.
Blackwell already moved that number dramatically compared to prior generations. But Vera Rubin makes Blackwell look like a hand-cranked calculator. NVIDIA’s benchmarks show the Vera Rubin NVL72 delivering one-tenth the cost per million tokens compared to a Blackwell NVL72 rack. Not 10% better. Not twice as good. One-tenth the cost.
Back to the analogy: if Einstein can produce a breakthrough insight for $1, the substitute teacher charges $10 for a far less useful answer. You are paying ten times more for a fraction of the intelligence. That is not a hardware purchasing decision. That is a strategic liability hiding in your CapEx budget.
“The question is not whether you can afford NVIDIA’s best chips. It’s whether you can afford to run an AI factory staffed by anything less.”
GPU Performance at a Glance
| Metric | Hopper (H100) | Blackwell (GB200) | Vera Rubin |
|---|---|---|---|
| Inference Performance | ~2 PFLOPS FP8 | 10 PFLOPS NVFP4 | 50 PFLOPS NVFP4 |
| Training Performance | ~1 PFLOPS | 10 PFLOPS NVFP4 | 35 PFLOPS NVFP4 |
| Cost Per Million Tokens (Relative) | 10x baseline | ~1x baseline | ~0.1x baseline |
| GPUs to Train MoE Models (vs. Blackwell) | 4x more | Baseline | 75% fewer |
| Memory Bandwidth (per GPU) | 3.35 TB/s | 8 TB/s | 22 TB/s (HBM4) |
| The Analogy | Competent Grad Student | Tenured PhD Physicist | Albert Einstein |
The Leverage Machine: Why the GPU Price Is Almost Irrelevant
Here is the most important economic insight in all of AI infrastructure, and it is almost never stated plainly: the GPU is a portion of what you spend to build an AI data center, but it is the only portion that produces revenue.
Consider the full cost of building a serious AI facility. The building, the power infrastructure, the cooling systems, the networking, the land, the labor — all of it must exist before a single token is generated. For a 100-megawatt hyperscale AI facility, those fixed costs alone run between $900 million and $1.5 billion before a single GPU is racked.
Sample 100 MW AI Data Center: Total Buildout Cost Breakdown
| Cost Category | Estimated Range | % of Total CapEx | Produces Tokens? |
|---|---|---|---|
| Land & Site Preparation | $50M – $150M | ~8% | No |
| Building Shell & Civil Construction | $200M – $400M | ~20% | No |
| Power Infrastructure (generation, UPS, switchgear) | $300M – $500M | ~25% | No |
| Cooling Systems (liquid cooling, chillers, CDUs) | $150M – $300M | ~15% | No |
| Networking & Fiber | $100M – $200M | ~8% | No |
| IT Equipment — GPUs & Servers | $700M – $1.2B | ~40–50% | YES — Only This |
| Security, Compliance & Fit-Out | $50M – $100M | ~4% | No |
| Labor & Project Management | $100M – $200M | ~8% | No |
| Total Estimated CapEx | $1.65B – $3.05B | — | — |
Look at that table carefully. Roughly half of every dollar spent on an AI data center goes to infrastructure that produces nothing on its own. It is the stage. The GPUs are the performers. The building does not think. The cooling system does not reason. The fiber does not generate insights. All of that fixed cost exists for one purpose: to keep the GPUs running.
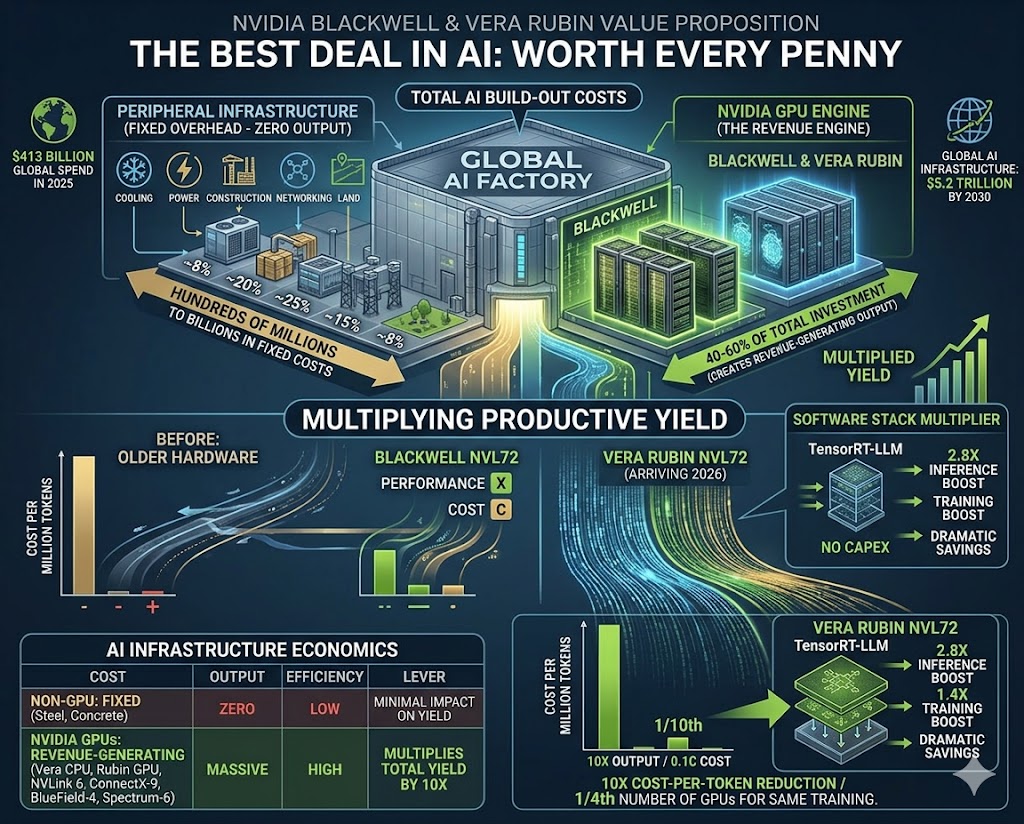
This creates extraordinary leverage. If you swap in GPUs that produce ten times more output for the same infrastructure envelope, you have effectively multiplied the productive yield of your entire billion-dollar investment by 10x. The building didn’t get more expensive. The power didn’t cost more. The land didn’t change. You just put Einstein in the room instead of the substitute teacher — and suddenly everything you already paid for starts working ten times harder.
“When Vera Rubin cuts cost per token by 10x, it doesn’t just improve a line item — it multiplies the return on every dollar of fixed infrastructure already spent.”
The Operator Math: What 10x Really Means in Revenue Terms
Let’s make this concrete. Suppose you’re an AI cloud operator running inference-as-a-service. You’ve built a mid-scale cluster and your customers pay per token.
| Blackwell Deployment | Vera Rubin Deployment | |
|---|---|---|
| GPU Racks | 10 racks × ~$3M | 10 racks × ~$4–5M (est.) |
| GPU Hardware Cost | ~$30M | ~$40–50M |
| Fixed Infrastructure (power, cooling, build) | ~$40M | ~$40M (same) |
| Total Buildout | ~$70M | ~$80–90M |
| Daily Token Output (Relative) | 1x | Up to 10x |
| Revenue Capacity Per Day (Relative) | 1x | Up to 10x |
| Cost Per Million Tokens (Relative) | 1x | ~0.1x |
| Payback on GPU Premium | — | Rapid, via 10x output capacity |
The operator spending $10–20 million more on Vera Rubin hardware, against the same $40 million fixed infrastructure base, gets back an order-of-magnitude expansion in productive capacity. The same stage, the same lights, the same venue — but now Einstein is performing ten shows a night instead of one.
That’s not an incremental upgrade. That’s a business model transformation.
The Hidden Bonus: The Chips Keep Getting Smarter After You Buy Them
One of the most underappreciated aspects of NVIDIA’s platform is what happens after you buy the hardware. Since Blackwell’s initial launch, NVIDIA has delivered a 2.8x inference improvement and a 1.4x training boost purely through software updates to TensorRT-LLM — no new hardware required. Organizations running existing Blackwell clusters can capture those gains today, simply by updating their software stack.
Think of it this way: you hired Einstein, and then he kept taking night classes. Every few months, he comes back slightly smarter, faster, and more efficient — at no additional cost to you. The substitute teacher you hired from the competing vendor? He peaked on day one.
Vera Rubin extends this philosophy with deeper hardware-software co-design, including NVFP4 precision formats that squeeze more useful computation out of every transistor. The architecture is designed so that software advances translate directly into real-world throughput gains — not just benchmark numbers that disappear in production.
“You hired Einstein, and then he kept taking night classes. Every few months, he comes back smarter — at no additional charge.”
Why a “Cheaper” Chip Is Often More Expensive
A common objection to NVIDIA’s pricing is that alternatives cost less per chip. It’s a fair observation that leads to an unfair conclusion.
Vera Rubin is not a GPU. It is a six-chip co-designed ecosystem: the Vera CPU, the Rubin GPU, the NVLink 6 Switch, the ConnectX-9 SuperNIC, the BlueField-4 DPU, and the Spectrum-6 Ethernet Switch. Every component was engineered specifically to work with the others, delivering 260 terabytes per second of scale-up bandwidth and 22 terabytes per second of HBM4 memory bandwidth per GPU.
An alternative accelerator that costs 30% less per chip but requires four times as many chips, plus additional networking, plus more complex cooling, plus a software stack that needs constant hand-tuning, is not cheaper. It is more expensive — it just distributes the cost across more categories and more labor hours, making the true price harder to see on a single line item.
It’s like hiring four mediocre accountants because each one costs less than a top-tier CFO. The payroll looks lower. The quality of your financial strategy is catastrophically worse. And now you’re managing four people instead of one.
The Macro Picture: Why This Matters Beyond Any Single Company
The investment flowing into AI infrastructure today is historically unprecedented. The four major hyperscalers — Microsoft, Google, Amazon, and Meta — collectively spent roughly $413 billion on AI data centers in 2025. Spending is projected to rise to $600–700 billion in 2026. McKinsey estimates global AI infrastructure investment will reach $5.2 trillion by 2030.
In that context, every 10x improvement in cost per token is not a product feature — it is a multi-trillion dollar economic event. It determines whether the AI factories being built today generate returns or write-downs. It determines whether AI applications reach price points that drive genuine mass adoption. It determines which companies and industries lead the next twenty years of economic growth.
Blackwell and Vera Rubin are not just chips. They are the difference between AI remaining an expensive research project and AI becoming as economically accessible as electricity.
The Verdict: Stop Asking If You Can Afford It
NVIDIA’s Blackwell and Vera Rubin chips are expensive. A single Blackwell NVL72 rack approaches $3 million. Vera Rubin will cost more. Nobody is pretending otherwise.
But “can I afford this chip?” is the wrong question. The right question is: “what does every other dollar I spend on AI infrastructure cost me if I don’t put the best possible GPU at the center of it?”
A billion-dollar data center built around second-tier compute is a billion-dollar stage built for the substitute teacher. The building, the power, the cooling, the fiber — all of it performs at the ceiling of whatever intelligence you place inside it. Put in the substitute teacher, and that’s what your billion dollars produces. Put in Einstein, and the returns compound on every dollar already spent.
Vera Rubin delivers one-tenth the cost per token. Five times the inference performance. Three and a half times the training throughput. On the same power budget, the same rack footprint, and the same infrastructure you were already planning to build.
The math is not complicated. The choice is not close. In the race to build the intelligence layer of the global economy, there is Blackwell and Vera Rubin on one side — and then, at a significant and measurable distance, everyone else.
Sources: NVIDIA Newsroom, GTC 2026 Keynote, Tom’s Hardware, VentureBeat, McKinsey & Company, Alpha Matica, Motley Fool Research, VideoCardz, NVIDIA Developer Blog. Performance figures based on NVIDIA-published benchmarks. Real-world results may vary.



